Viewpoint-Conditioned Legible Motion Planning with Imitation and Reinforcement Learning
AI and Manipulation

In robotics, legible motion planning is crucial for effective human-robot interaction and shared autonomy. It involves designing robotic movements that are easily interpretable by humans, promoting intuitive anticipation of a robot's actions. This is essential in settings where robots and humans work closely together, such as in collaborative manufacturing or healthcare.
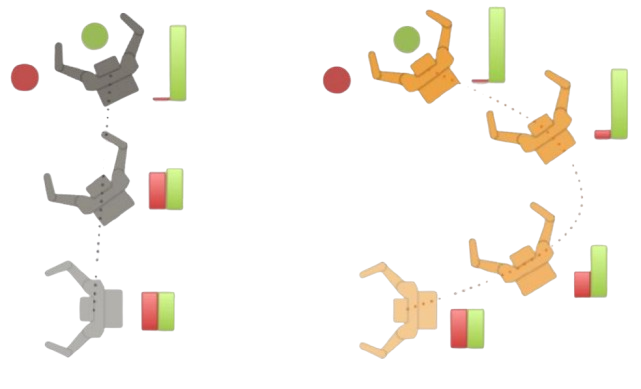
Two key learning-based methods for achieving legible motion are reinforcement learning (RL) and imitation learning (IL):
- Reinforcement Learning (RL) uses a trial-and-error approach with rewards and penalties to teach robots optimal behaviors, allowing for adaptive and autonomous learning.
- Imitation Learning (IL) involves teaching robots by mimicking human demonstrations, aligning robotic actions with human-like patterns.
However, both methods have been applied largely ignoring the influence of the observer’s viewpoint, which affects how clearly the robot’s intent is communicated. The research aims to integrate viewpoint conditioning into these learning algorithms to improve the alignment of robotic behavior with human perception.
The project introduces:
- A universal planning architecture that incorporates both RL and IL for learned legibility.
- A new model of legible motion planning that considers the human viewpoint.
- Evaluations demonstrating the effectiveness of these approaches in real-world scenarios.
The goal is to enhance human-robot collaboration by making robotic actions more predictable and understandable.
System Overview
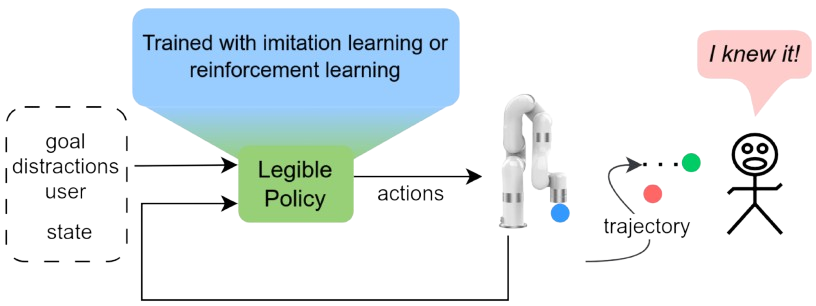
We propose a universal learning-based architecture for legible motion planning that can be applied across both reinforcement learning (RL) and imitation learning (IL) setups, differing primarily in the policy learning pipeline. Our focus is on goal-reaching manipulation tasks where the robot must choose between two objects: a goal and a distraction. To ensure legibility, the robot’s movements must be easily understandable and predictable by humans, indicating which object it aims to reach. Furthermore, the robot’s actions are adjusted based on the human’s perspective of the task environment, whether viewed from above or the side.
In our proposed framework, the policy—trainable via either imitation learning or reinforcement learning—generates legible motions that allow human collaborators to clearly grasp the robot’s intent. At each time step, the policy receives inputs including the state of the robot, the goal, potential distractions that could confuse human collaborators, and the viewpoint of the human collaborators. It then predicts an action in the form of joint torques for the robot to execute. While our focus is on the planning side, all observations except the robot state are specified manually. In practical applications, these observations can be obtained from a perception module to facilitate full shared autonomy.
Technical Approaches
Reinforcement Learning-Based Approach

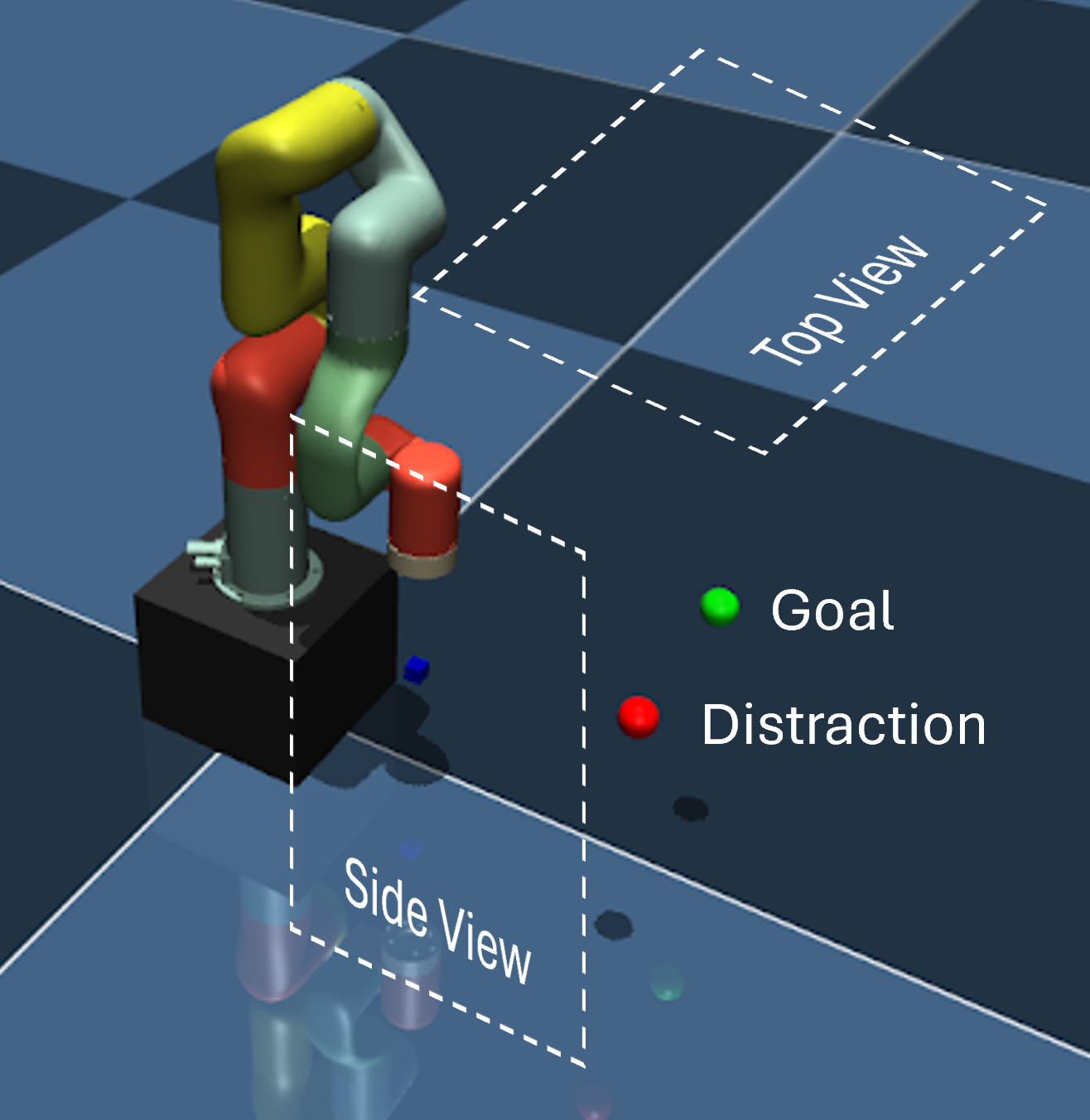
Simulation setup for RL with the xArm robot. We use Mujoco as the physics engine and interface it through Gym for learning algorithms. The blue, green and red dots represent the positions of the end effector, goal and distraction, respectively. In human evaluation, we create videos of the same setup with the side and the top view.
Imitation Learning-Based Approach
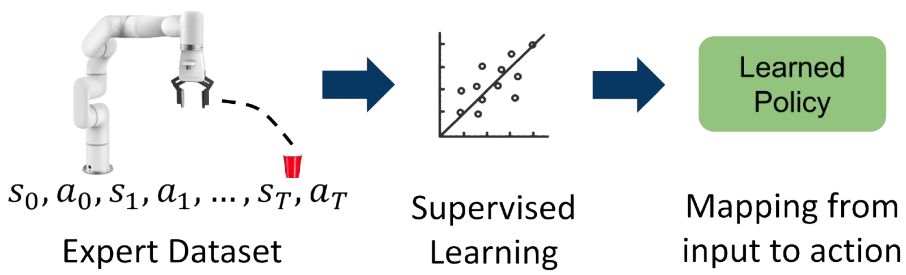
Toy experimental setup for testing IL model with the xArm robot. The setup shows a reaching task towards the object as goal while legibly avoid the red object as distraction. The model also accommodate to different viewpoint condition as we have the same set up with the top and the side view in human evaluation.

Results
Reinforcement Learning Results

Side view of reinforcement learning trajectory.

Top view of reinforcement learning trajectory.
Imitation Learning Results

Side view of imitation learning legible trajectory.

Top view of imitation learning legible trajectory.
Evaluation
Since legibility refers to the ability to generate motion sequences that are easily understood by humans, creating a metric that accurately reflects human preferences is challenging. Therefore, it is essential to include human evaluation alongside the metrics used in our RL and IL training processes. A group of 10 participants was asked to watch all 8 videos, pausing when they believed they had identified the robot’s intention, and then reporting which object they thought the robot was targeting. We developed a scoring system to balance these considerations.
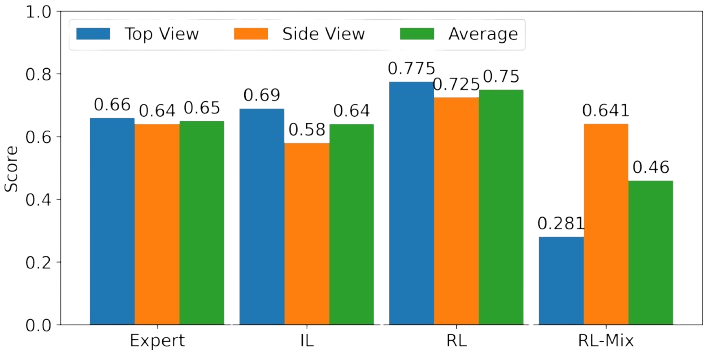
Human-based evaluation results on the recorded legible motions. While IL-trained agent performed competitively well compared to the expert demonstrations, RL-trained one outperformed the others by 15%. Without proper viewpoint conditioning, RL-trained agent obtained a low score.
Conclusion
- Accomplished goal-oriented tasks with legible motion plans considering observer’s viewpoint
- Evaluated two learning-based methods with humans and compared with expert baseline
Future Work
- Bridge the gap between simulation and real world for RL.
- Integrate multi-modal sensory inputs for adaptive and dynamic legible motion.